This analysis will statistically demonstrate that some players are more likely to hit into errors than others.
Errors are uncommon, so players hit into errors very infrequently. Estimating the likelihood of an infrequent event is hard and requires lots of data. To acquire as much data as possible, I wrote a bash script that will download data for all players between 1970 and 2018.
This data enables me to use data from multiple years for each player, giving me more data when estimating how likely a particular player is to hit into an error.
1 2 3 4 5 6 7 8 9 10 11 12 | |
The data has 5 columns: playerid, playername, errors hit into, balls hit into play (BIP), and year. The file does not have a header.
1 2 | |
aaroh101, Hank Aaron, 8, 453, 1970
aarot101, Tommie Aaron, 0, 53, 1970
abert101, Ted Abernathy, 0, 10, 1970
adaij101, Jerry Adair, 0, 24, 1970
ageet101, Tommie Agee, 12, 480, 1970
akerj102, Jack Aker, 0, 10, 1970
alcal101, Luis Alcaraz, 1, 107, 1970
alleb105, Bernie Allen, 1, 240, 1970
alled101, Dick Allen, 4, 341, 1970
alleg101, Gene Alley, 6, 356, 1970
I can load the data into pandas using the following command.
1 2 3 4 5 | |
1
| |
| playerid | player_name | errors | bip | year | |
|---|---|---|---|---|---|
| 0 | aaroh101 | Hank Aaron | 8 | 453 | 1970 |
| 1 | aarot101 | Tommie Aaron | 0 | 53 | 1970 |
| 2 | abert101 | Ted Abernathy | 0 | 10 | 1970 |
| 3 | adaij101 | Jerry Adair | 0 | 24 | 1970 |
| 4 | ageet101 | Tommie Agee | 12 | 480 | 1970 |
1
| |
38870
I have almost 39,000 year, player combinations…. a good amount of data to play with.
While exploring the data, I noticed that players hit into errors less frequently now than they used to. Let’s see how the probability that a player hits into an error has changed across the years.
1 2 3 4 5 6 7 8 9 10 11 12 | |
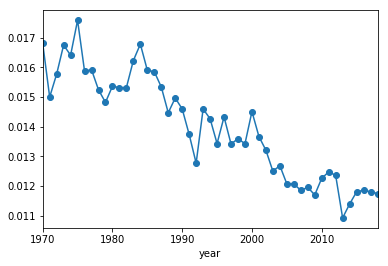
Interestingly, the proportion of errors per BIP has been dropping over time. I am not sure if this is a conscious effort by MLB score keepers, a change in how hitters hit, or improved fielding (but I suspect it’s the score keepers). It looks like this drop in errors per BIP leveled off around 2015. Zooming in.
1
| |
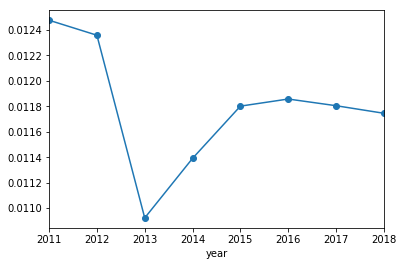
I explore this statistically in a jupyter notebook on my github.
Because I don’t want year to confound the analysis, I remove all data before 2015.
1
| |
1
| |
3591
This leaves me with 3500 year, player combinations.
Next I combine players’ data across years.
1
| |
1
| |
| errors | bip | |
|---|---|---|
| count | 1552.000000 | 1552.000000 |
| mean | 3.835052 | 324.950387 |
| std | 6.073256 | 494.688755 |
| min | 0.000000 | 1.000000 |
| 25% | 0.000000 | 7.000000 |
| 50% | 1.000000 | 69.000000 |
| 75% | 5.000000 | 437.000000 |
| max | 37.000000 | 2102.000000 |
I want an idea for how likely players are to hit into errors.
1 2 3 | |
0.011801960251664112
Again, errors are very rare, so I want know how many “trials” (BIP) I need for a reasonable estimate of how likely each player is to hit into an error.
I’d like the majority of players to have at least 5 errors. I can estimate how many BIP that would require.
1
| |
423.65843413978496
Looks like I should require at least 425 BIP for each player. I round this to 500.
1
| |
1
| |
1
| |
| playerid | player_name | errors | bip | |
|---|---|---|---|---|
| 0 | abrej003 | Jose Abreu | 20 | 1864 |
| 1 | adamm002 | Matt Adams | 6 | 834 |
| 2 | adrie001 | Ehire Adrianza | 2 | 533 |
| 3 | aguij001 | Jesus Aguilar | 2 | 551 |
| 4 | ahmen001 | Nick Ahmed | 12 | 1101 |
1
| |
| errors | bip | |
|---|---|---|
| count | 354.000000 | 354.000000 |
| mean | 12.991525 | 1129.059322 |
| std | 6.447648 | 428.485467 |
| min | 1.000000 | 503.000000 |
| 25% | 8.000000 | 747.250000 |
| 50% | 12.000000 | 1112.000000 |
| 75% | 17.000000 | 1475.750000 |
| max | 37.000000 | 2102.000000 |
I’ve identified 354 players who have enough BIP for me to estimate how frequently they hit into errors.
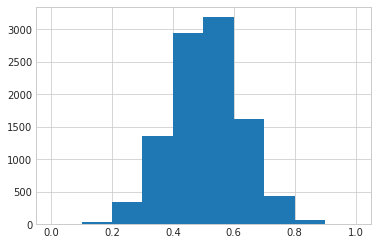
Below, I plot how the likelihood of hitting into errors is distributed.
1 2 3 4 | |
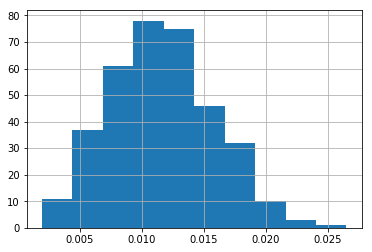
The question is whether someone who has hit into errors in 2% of their BIP is more likely to hit into an error than someone who has hit into errors in 0.5% of their BIP (or is this all just random variation).
To try and estimate this, I treat each BIP as a Bernoulli trial. Hitting into an error is a “success”. I use a Binomial distribution to model the number of “successes”. I would like to know if different players are more or less likely to hit into errors. To do this, I model each player as having their own Binomial distribution and ask whether p (the probability of success) differs across players.
To answer this question, I could use a chi square contingency test but this would only tell me whether players differ at all and not which players differ.
The traditional way to identify which players differ is to do pairwise comparisons, but this would result in TONS of comparisons making false positives all but certain.
Another option is to harness Bayesian statistics and build a Hierarchical Beta-Binomial model. The intuition is that each player’s probability of hitting into an error is drawn from a Beta distribution. I want to know whether these Beta distributions are different. I then assume I can best estimate a player’s Beta distribution by using that particular player’s data AND data from all players together.
The model is built so that as I accrue data about a particular player, I will trust that data more and more, relying less and less on data from all players. This is called partial pooling. Here’s a useful explanation.
I largely based my analysis on this tutorial. Reference the tutorial for an explanation of how I choose my priors. I ended up using a greater lambda value (because the model sampled better) in the Exponential prior, and while this did lead to more extreme estimates of error likelihood, it didn’t change the basic story.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [rates, kappa_log, phi]
Sampling 2 chains: 100%|██████████| 6000/6000 [01:47<00:00, 28.06draws/s]
Check whether the model converged.
1
| |
1.0022635936332533
1 2 3 | |
The most challenging parameter to fit is kappa which modulates for the variance in the likelihood to hit into an error. I take a look at it to make sure things look as expected.
1
| |
| mean | sd | mc_error | hpd_2.5 | hpd_97.5 | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| kappa | 927.587178 | 141.027597 | 4.373954 | 657.066554 | 1201.922608 | 980.288914 | 1.000013 |
1
| |

I can also look at phi, the estimated global likelihood to hit into an error.
1
| |

Finally, I can look at how all players vary in their likelihood to hit into an error.
1
| |
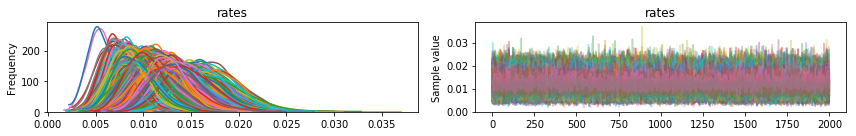
Obviously, the above plot is a lot to look at it, so let’s order players by how likely the model believes they are to hit in an error.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
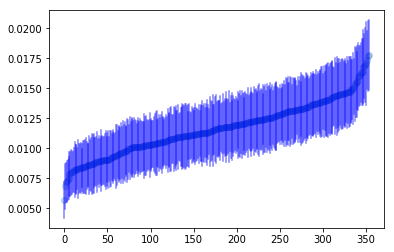
Now, the ten players who are most likely to hit into an error.
1 2 3 | |
| playerid | player_name | errors | bip | prop_error | estimated_mean | |
|---|---|---|---|---|---|---|
| 71 | corrc001 | Carlos Correa | 30 | 1368 | 0.021930 | 0.017838 |
| 227 | myerw001 | Wil Myers | 27 | 1214 | 0.022241 | 0.017724 |
| 15 | andre001 | Elvis Andrus | 37 | 1825 | 0.020274 | 0.017420 |
| 258 | plawk001 | Kevin Plawecki | 14 | 528 | 0.026515 | 0.017200 |
| 285 | rojam002 | Miguel Rojas | 21 | 952 | 0.022059 | 0.017001 |
| 118 | garca003 | Avisail Garcia | 28 | 1371 | 0.020423 | 0.016920 |
| 244 | pench001 | Hunter Pence | 22 | 1026 | 0.021442 | 0.016875 |
| 20 | baezj001 | Javier Baez | 23 | 1129 | 0.020372 | 0.016443 |
| 335 | turnt001 | Trea Turner | 23 | 1140 | 0.020175 | 0.016372 |
| 50 | cainl001 | Lorenzo Cain | 32 | 1695 | 0.018879 | 0.016332 |
And the 10 players who are least likely to hit in an error.
1 2 3 | |
| playerid | player_name | errors | bip | prop_error | estimated_mean | |
|---|---|---|---|---|---|---|
| 226 | murpd006 | Daniel Murphy | 4 | 1680 | 0.002381 | 0.005670 |
| 223 | morrl001 | Logan Morrison | 4 | 1241 | 0.003223 | 0.006832 |
| 343 | vottj001 | Joey Votto | 8 | 1724 | 0.004640 | 0.007112 |
| 239 | panij002 | Joe Panik | 7 | 1542 | 0.004540 | 0.007245 |
| 51 | calhk001 | Kole Calhoun | 9 | 1735 | 0.005187 | 0.007413 |
| 55 | carpm002 | Matt Carpenter | 8 | 1566 | 0.005109 | 0.007534 |
| 142 | hamib001 | Billy Hamilton | 8 | 1476 | 0.005420 | 0.007822 |
| 289 | rosae001 | Eddie Rosario | 8 | 1470 | 0.005442 | 0.007855 |
| 275 | renda001 | Anthony Rendon | 9 | 1564 | 0.005754 | 0.007966 |
| 8 | alony001 | Yonder Alonso | 8 | 1440 | 0.005556 | 0.008011 |
It looks to me like players who hit more ground balls are more likely to hit into an error than players who predominately hits fly balls and line-drives. This makes sense since infielders make more errors than outfielders.
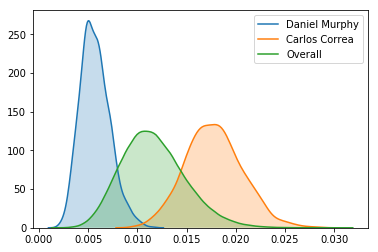
Using the posterior distribution of estimated likelihoods to hit into an error, I can assign a probability to whether Carlos Correa is more likely to hit into an error than Daniel Murphy.
1
| |
0.0
The model believes Correa is much more likely to hit into an error than Murphy!
I can also plot these players’ posterior distributions.
1 2 3 4 5 | |
Finally, I can look exclusively at how the posterior distributions of the ten most likely and 10 least likely players to hit into an error compare.
1 2 | |
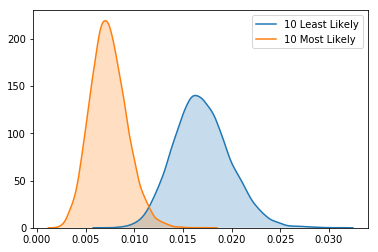
All in all, this analysis makes it obvious that some players are more likely to hit into errors than other players. This is probably driven by how often players hit ground balls.
]]>